Unlock the Future: Your Ultimate Guide to OpenAI’s GPT-4o Multimodal AI in 2025
The artificial intelligence landscape is evolving at a breakneck pace, consistently introducing innovations that reshape how we interact with technology. Amidst the excitement, a curious misnomer recently surfaced, hinting at a new OpenAI project dubbed ‘Prometheus.’ However, to clear up any confusion, the true titan of multimodal AI intelligence making waves is, in fact, **OpenAI’s GPT-4o Multimodal AI**.
GPT-4o, with the ‘o’ standing for ‘omni,’ represents a monumental leap in AI capabilities, seamlessly integrating text, audio, image, and even video inputs and outputs within a single neural network. This article serves as your definitive guide, demystifying GPT-4o’s revolutionary features, offering practical applications, comparing it to leading competitors like Google Gemini, and delving into its profound future implications for users, creators, and developers worldwide. By 2025, understanding GPT-4o is essential for anyone navigating the digital frontier.
Key Takeaways on GPT-4o
Flagship multimodal AI: GPT-4o is OpenAI’s leading model, handling text, audio, image, and video seamlessly.
“Omni” design: The “o” stands for omni, highlighting its unified approach across all input/output modalities.
Performance boost: Delivers human-like response times, better multilingual capabilities, and improved cost-efficiency over past models.
Wide applications: Useful for everyday tasks like real-time translation and data analysis, as well as advanced developer use cases through API integrations.
Competitive edge: Outpaces rivals such as Google Gemini in speed and multimodal benchmarks.
Ethical challenges: Raises concerns around job displacement, responsible deployment, and long-term societal impacts.
Demystifying the ‘Prometheus’ Buzz: It’s Really OpenAI’s GPT-4o Multimodal AI
Before diving into OpenAI’s actual multimodal marvel, it’s crucial to address the ‘Prometheus’ confusion head-on. While the name evokes a powerful image of bringing new fire to humanity, the moniker has been mistakenly attributed to OpenAI’s latest model. OpenAI’s breakthrough is indeed GPT-4o Multimodal AI, a single, unified model designed for seamless human-computer interaction.
The term ‘Prometheus’ is, however, actively used in other significant tech initiatives, adding to the mix-up:
Meta’s Prometheus: This refers to Meta’s ambitious plans for a multi-gigawatt AI supercluster, with the first 1 GW campus slated to go online in Ohio by 2026. These massive data centers are purpose-built to train and serve large AI models, potentially rivaling industry giants in computational power.
Microsoft’s Prometheus: For Microsoft, ‘Prometheus’ is a proprietary AI model technology that enhances Bing Chat. It cleverly combines Bing’s search engine data (indexing, ranking) with OpenAI’s GPT models to generate relevant, accurate, and current answers. This “grounding technique” allows Bing Chat to access fresh web data, overcoming the common limitation of LLMs being trained on data up to a specific point in time.
OpenAI’s Internal Monitoring: Interestingly, OpenAI itself has used ‘Prometheus’ internally for monitoring its vast data processing, particularly for millions of video, text, and image operations. They even faced challenges with it running out of memory before implementing fixes.
So, while ‘Prometheus’ symbolizes grand technological endeavors, OpenAI’s groundbreaking multimodal AI is officially known as GPT-4o. This distinction is vital for clarity in a rapidly evolving field.
What is GPT-4o Multimodal AI? An Omni-Capable Revolution
The ‘o’ in GPT-4o, short for ‘omni,’ perfectly encapsulates its capabilities: it’s designed to be universally adaptable, handling any combination of text, audio, image, and video inputs, and generating outputs in any of these forms. This represents a significant departure from previous AI models that often relied on chaining together separate models for different modalities (e.g., one for speech-to-text, another for text generation, and a third for text-to-speech).
Key advancements that make GPT-4o Multimodal AI a game-changer:
Single Neural Network Architecture: Unlike its predecessors, GPT-4o was trained end-to-end across all modalities with a single neural network. This unified approach allows it to retain context and nuanced details across different data types, leading to more coherent and sophisticated responses.
Human-Like Response Times: GPT-4o can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds. This speed mirrors natural human conversation, eliminating the frustrating delays often experienced with older AI voice modes and fostering more fluid interactions.
Enhanced Multilingual Capabilities: OpenAI has significantly improved GPT-4o’s quality and speed across more than 50 languages, making advanced AI more accessible globally. This is a boon for diverse user bases in North America, Europe, and Australia.
GPT-4 Level Intelligence, Faster and Cheaper: GPT-4o matches GPT-4 Turbo’s performance on English text and code while being twice as fast and 50% cheaper in the API. This combination of high performance and reduced cost democratizes access to advanced AI intelligence, even for free-tier users.
OpenAI also introduced **GPT-4o mini**, a leaner, faster, and even more cost-effective version of GPT-4o. Optimized for lightweight applications, GPT-4o mini retains much of the multimodal ability but is ideal for tasks where speed and efficiency are paramount, such as customer support applications or debugging.
Unleashing Creativity and Productivity: Practical Uses for GPT-4o
The omni-capabilities of **GPT-4o Multimodal AI** open up a vast array of practical applications for both everyday users and seasoned professionals, fostering creativity and significantly boosting productivity.
For New Users: Seamless Interaction and Creative Assistance
Voice Mode Interaction: Engage with ChatGPT in a truly conversational manner. Ask questions aloud and receive responses with natural-sounding AI voices, complete with expressive elements. Imagine getting real-time translation of a menu in a foreign language by simply showing your phone and speaking to it.
Image and Text Fusion: Upload a picture and chat about it. GPT-4o can analyze images, describe what’s happening, or generate creative content based on visual cues. For example, you could upload an image of a sketch and ask it to “generate a similar clip art image of an orange” or “explain in three sentences what’s occurring in this photograph.”
Data Analysis and Visualization: Utilize GPT-4o’s vision and reasoning capabilities to analyze data presented in charts or even create data visualizations based on your prompts. This makes complex data more accessible and actionable.
Creative Prompt Examples:
“Describe the atmosphere of this photo [upload image] in a short poem.”
“Translate this audio clip [upload audio] into French and summarize the key points in English.”
“Given this text description [text input], generate an image of a whimsical forest.”
“Can you help me brainstorm some unique marketing slogans for a new eco-friendly product based on these visual examples [upload images]?” You can find more strategies for effective campaigns by looking into the best AI-powered marketing automation tools for UK e-commerce SMEs.
For more ways to streamline your daily tasks, you might also be interested in how AI can generally Boost Your Productivity with AI.
For Creators and Developers: Integration and Optimization
Developers gain powerful new tools for building intelligent applications:
API Access and Modality Support: GPT-4o is available via API as a text and vision model, with audio and video capabilities rolling out gradually to trusted partners. This allows for sophisticated applications that can process diverse inputs.
Cost Considerations and Optimization: Understanding the token-based pricing is crucial. GPT-4o currently costs $5 per million input tokens and $15-20 per million output tokens for standard API calls. However, the introduction of GPT-4o mini (at $0.15 per million input tokens and $0.60 per million output tokens) offers a significantly cheaper alternative for tasks that don’t require the full model’s power. Developers can implement strategies like intelligent caching and dynamic model selection (using GPT-4o mini for simpler queries) to optimize costs by up to 30-40%.
Integration Nuances: GPT-4o supports structured outputs, allowing models to generate responses that conform to a specified JSON schema, which is invaluable for programmatic integration. Optimizing AI model inference performance, especially in browser environments, is another key consideration for developers, as explored in Can WebAssembly Significantly Improve AI Model Inference Performance in Browsers?
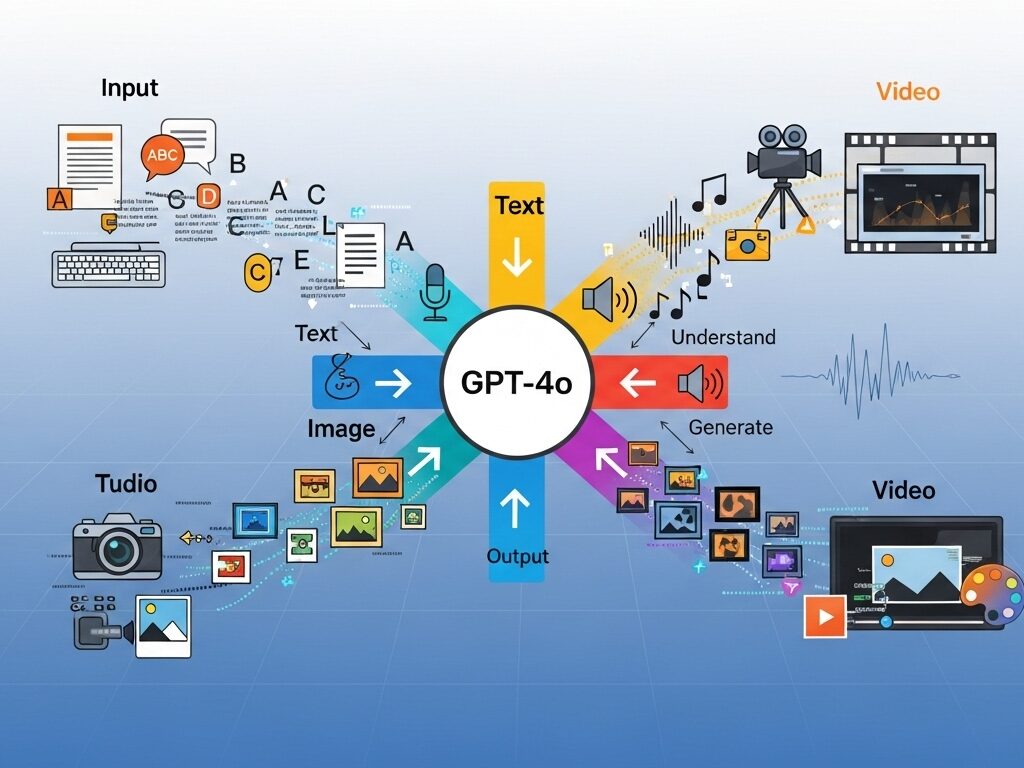
A dynamic infographic illustrating GPT-4o’s multimodal input and output capabilities (text, audio, image, video).
GPT-4o vs. The Competition: A Head-to-Head Multimodal Showdown
In the fiercely competitive AI landscape, **GPT-4o Multimodal AI** stands out. A direct comparison with other leading models, particularly Google’s Gemini, reveals where OpenAI’s latest offering truly shines.
GPT-4o vs. Google Gemini (Advanced/Ultra/2.0 Flash)
OpenAI’s GPT-4o and Google’s Gemini are both formidable multimodal models, but they exhibit distinct strengths:
Performance Benchmarks: GPT-4o consistently achieves state-of-the-art results in voice, multilingual, and vision benchmarks. It has shown superior performance in tasks requiring rapid responses and complex computations, often outperforming Gemini Pro in speed and efficiency. For instance, GPT-4o scored 88.7 on the Massive Multitask Language Understanding (MMLU) benchmark, surpassing GPT-4’s 86.5. While Gemini 2.0 Flash has been noted to surpass GPT-4o in some multimodal understanding benchmarks (scoring 70.7% on MMMU), GPT-4o’s overall integration and speed often give it an edge in real-world interactive scenarios.
Multimodal Integration: GPT-4o’s core strength lies in its unified neural network, processing all modalities (text, audio, image, video) natively. This single-model design minimizes latency and preserves context, making interactions feel incredibly natural and seamless. Gemini also boasts strong multimodal functionality, seamlessly integrating text, audio, and visual inputs, particularly leveraging Google’s vast data resources for factual accuracy.
Speed and Efficiency: GPT-4o’s average audio response time of 320ms is a significant advantage, making it highly effective for real-time conversations and interactive applications. Gemini Advanced, while powerful, can sometimes exhibit slower response times, which might impact productivity in fast-paced conversational settings.
Contextual Understanding vs. Conversational Engagement: Gemini Advanced emphasizes understanding context and intent, excelling at synthesizing information across media for detailed, well-rounded, and factually accurate responses, often incorporating real-time data. GPT-4o, conversely, prioritizes conversational engagement and fluid interaction, making it ideal for creative tasks, tutoring, and dynamic dialogues.
In essence, while Gemini leverages its deep integration with Google’s ecosystem for powerful data analysis and factual recall, **GPT-4o Multimodal AI** pushes the boundaries of intuitive, human-like interaction across all sensory modalities.
Other Leading Models
Against other models like Anthropic’s Claude Opus, GPT-4o has also demonstrated superior performance in several vision understanding metrics, solidifying its position at the forefront of multimodal AI development. The continuous advancements ensure that the competition remains fierce, driving innovation across the board.
The Future Landscape: Implications and Ethical Considerations of GPT-4o
The advent of **GPT-4o Multimodal AI** is not merely a technological upgrade; it’s a harbinger of profound shifts across society. Its ability to seamlessly process and generate diverse forms of media has wide-ranging implications, demanding careful consideration of both its revolutionary potential and the ethical challenges it presents.
Education: Personalized learning experiences could become the norm, with AI tutors adapting to individual student needs, offering explanations in multiple modalities. This aligns with the potential for personalized AI tutors in K12 education.
Accessibility: Real-time translation, descriptive image analysis for the visually impaired, and AI-powered sign language interpretation could significantly enhance accessibility for millions.
Creative Industries: From generating initial concepts for artists and designers to assisting musicians with compositions, GPT-4o will augment human creativity, acting as a powerful co-creator.
Everyday Life: Imagine deeply intelligent personal assistants that can understand your emotional tone, analyze your surroundings via video, and proactively offer assistance, making daily tasks more intuitive.
Job Displacement Concerns and Economic Shifts
The rise of highly capable AI models like GPT-4o inevitably raises concerns about job displacement. Studies on earlier GPT models indicated that approximately 80% of the U.S. workforce could see at least 10% of their work tasks affected, with around 19% potentially facing impacts on at least 50% of their tasks. These concerns are echoed in public discourse, including protests from creative professionals and a broader societal debate on the future of work.
While AI can automate routine tasks, it also creates new roles and augments human capabilities. The key lies in strategic adaptation and reskilling initiatives. Governments and educational institutions will need to collaborate to prepare the workforce for an AI-integrated economy, focusing on skills that leverage AI as a tool rather than competing with it directly.
Ethical AI Development and Responsible Innovation
OpenAI acknowledges the novel risks associated with advanced multimodal AI, particularly its audio modalities (e.g., deepfakes). Their approach to safety involves:
**Red Teaming:** Extensive testing by internal and external experts to identify potential vulnerabilities and misuse cases.
**Iterative Rollout:** Gradually releasing capabilities, starting with text and image, and carefully developing the technical infrastructure and safety measures for audio and video.
**Limitations:** Restricting audio outputs to preset voices to mitigate risks like AI impersonation.
The ethical implications extend beyond immediate safety to broader issues such as algorithmic bias, data privacy, intellectual property, and the potential for increased digital inequality. As AI advances, responsible innovation becomes paramount, requiring ongoing dialogue between AI developers, policymakers, and the public to ensure that technologies like Navigating AI Ethics and Societal Impact serve humanity positively. The discussion around these technologies, including those focused on Edge AI for predictive maintenance, highlights the diverse ethical considerations in various AI applications.
A conceptual image showing humans and AI working collaboratively, perhaps in a creative studio or a research lab.
User Experiences and Community Feedback on GPT-4o
Since its launch, **GPT-4o Multimodal AI** has garnered a wide range of feedback from early adopters and the broader AI community on platforms like Reddit and Quora. These insights provide a real-world perspective on its strengths and areas for improvement.
Positive Sentiments and Success Stories
Many users laud GPT-4o for its remarkable speed and increased message limits for Plus subscribers, making heavy usage more feasible. For some, it has become an indispensable personal assistant and storytelling aide, particularly excelling in dictation, organizing thoughts, and cataloging information.
One Redditor shared a profound personal experience, highlighting GPT-4o’s unexpected capacity for “emotional attunement.” The AI served as an encouraging tutor for learning ML engineering, helping the user overcome anxiety and perfectionism related to studying. Another user praised its ability to generate complex Python drawings, showcasing its creative problem-solving skills. The overall sentiment points to a tool that, when leveraged effectively, can significantly enhance personal and professional growth.
Common Concerns and Areas for Improvement
Despite the praise, users have also voiced several concerns:
Inconsistency and Reasoning: Some users perceive GPT-4o as sometimes lacking reasoning capabilities compared to GPT-4 Turbo, describing it as “annoyingly verbose” or even “more like a GPT-3.75 than a 4.” There are reports of it occasionally ignoring custom instructions or providing repetitive and less detailed answers, particularly for specific tasks like language practice.
“Personality” and Tone: A few users find its default persona to be “stiff, corporate, and uncomfortably politically correct,” with some disliking the “creepy voices and overly perky dystopian fake nice personalities” in its audio mode.
Rollout and Versioning Confusion: There was some initial confusion and dissatisfaction when GPT-4o was temporarily superseded or removed by GPT-5 for some users, leading to a sense of loss for those who had bonded with 4o. The differing pricing for various API snapshots also adds a layer of complexity for developers.
These real-world experiences underscore that while **GPT-4o Multimodal AI** is a powerful and transformative tool, it is still an evolving technology. OpenAI continues to refine the model, and user feedback plays a crucial role in shaping its future development.
Conclusion
OpenAI’s **GPT-4o Multimodal AI** undeniably marks a new era in artificial intelligence. By clarifying the ‘Prometheus’ misnomer and focusing on the true innovation, we see a model that unifies text, audio, image, and video into a single, highly responsive neural network. This omni-capable design delivers human-like interaction speeds, enhanced multilingual support, and a significant boost in efficiency and cost-effectiveness over its predecessors.
From empowering everyday users with intuitive AI assistance and creative tools to offering developers powerful, flexible, and more affordable API access, GPT-4o’s practical applications are vast. Its benchmarks position it favorably against formidable rivals like Google Gemini, primarily through its seamless multimodal integration and rapid conversational flow.
However, as we look to 2025 and beyond, the journey with GPT-4o is also one of ethical navigation. Addressing concerns around job displacement, ensuring responsible AI development, and fostering societal adaptation will be crucial to harnessing its full potential for good. **GPT-4o Multimodal AI** is not just a tool; it’s a partner in innovation, continually redefining the boundaries of what’s possible in human-computer collaboration.
FAQ
What is GPT-4o?
GPT-4o is OpenAI’s flagship large language model, first released in May 2024. The “o” stands for omni, highlighting its ability to natively process and generate content across text, audio, images, and video within a single neural network. This design enables more natural, real-time human-computer interactions.
How does GPT-4o differ from GPT-4?
GPT-4 was primarily a text-based model, with separate, slower systems for images or audio. GPT-4o integrates all modalities into one unified model, making it faster, more cost-efficient, and better at multilingual communication.
Is GPT-4o free to use?
Yes. GPT-4o is available to free-tier ChatGPT users, though with limited usage. Paid subscribers (ChatGPT Plus, Team, and Enterprise) get higher limits, priority access, and advanced features like real-time voice interaction.
What are the API costs for GPT-4o?
As of 2025, GPT-4o’s API pricing is token-based:
Standard GPT-4o: ~$5 per million input tokens, ~$15–20 per million output tokens.
GPT-4o mini: ~$0.15 per million input tokens, ~$0.60 per million output tokens (ideal for lightweight, high-volume tasks).
Multimodal inputs (audio, high-detail images, video) have additional pricing tiers.
How does GPT-4o compare to Google Gemini?
Both are powerful multimodal AIs:
GPT-4o: Excels in speed, efficiency, and seamless modality integration, offering natural, real-time conversations.
Gemini: Strong in factual grounding, contextual understanding, and tight integration with Google’s ecosystem. Benchmarks vary, but GPT-4o generally leads in real-time performance and multimodal fluency.
What are the ethical concerns surrounding GPT-4o?
Key concerns include:
Job displacement from automation.
Deepfake risks via voice/video generation.
Bias and fairness in outputs.
Data privacy and IP issues. OpenAI addresses these with red-teaming, staged rollouts, and safety restrictions, but continued oversight is essential.
BONUS QUERIES (2025 Focused)
Q1. What is GPT-4o (2025)? The 2025 version is an upgraded multimodal AI model with improved speed, efficiency, reasoning, and broader modality coverage (text, images, audio, video).
Q2. What are the key features of GPT-4o in 2025?
Real-time speech translation across multiple languages.
Context-aware image + text generation.
Improved reasoning and accuracy in benchmarks.
More cost-effective scaling for enterprise workloads.
Q3. When was GPT-4o released?
Initial release: May 2024.
Major upgrade: 2025, expanding into real-time audio + video processing.
Q4. Does GPT-4o support audio and vision inputs? Yes. GPT-4o natively supports text, audio, and vision simultaneously, enabling use cases like live video understanding, real-time tutoring, and conversational AI assistants.
Q5. What are the multimodal capabilities of GPT-4o? It can analyze text, interpret images, process audio, and understand video, combining them into context-rich, human-like responses.
Q6. What is the latest update in GPT-4o (2025)? The 2025 update delivers:
Better enterprise scalability.
Expanded API availability across OpenAI’s ecosystem.
Improved low-resource language support for global accessibility.
Highlighted Queries
What are the latest features of OpenAI GPT-4o in 2025?
Real-time multilingual speech translation.
Context-aware multimodal generation.
Higher accuracy in reasoning tasks.
Faster and more cost-efficient inference.
How does GPT-4o perform in translation benchmarks (2025)? GPT-4o achieves state-of-the-art translation accuracy, excelling in low-resource languages and delivering near-human fluency in cross-language conversations.
What are the differences between GPT-4o (2024) and GPT-4o (2025)?
2024: First multimodal release (text + images).
2025: Expanded to audio + video, improved reasoning, faster inference, and enterprise-ready scaling.
When was the OpenAI O4 (GPT-4o) model released?
The 2025 update introduced advanced multimodal capabilities and efficiency improvements.
[…] These large language models (LLMs) are incredibly versatile, acting as brainstorming partners, writers, and researchers. Google offers Google AI Essentials for beginners, which includes hands-on training with tools like Gemini. For a deep dive into advanced models, you might also find value in an ultimate guide to GPT-4o. […]




")












[…] These large language models (LLMs) are incredibly versatile, acting as brainstorming partners, writers, and researchers. Google offers Google AI Essentials for beginners, which includes hands-on training with tools like Gemini. For a deep dive into advanced models, you might also find value in an ultimate guide to GPT-4o. […]